
[AWS] EventBridge Rules による ECS Scheduled Task はエラー時リトライできない
なので Step Functions を使いましょうと言うお話です。
ある ECS で動いているバッチジョブの定期実行に EventBridge Rules を使って実装していたのですが、ある時ジョブがほぼ一定の頻度で失敗している事に気づきました。
AWS サポートに問い合わせると、今回のケースでは EventBridge Rules ではリトライできないので、 Step Functions を間に噛ませて下さいとご提案頂いたので、今回はその様にしました。
それでは以下経緯を交えながら実際のアーキテクチャをご紹介していきます。
構成
- ECS クラスタは Fargate ではなく EC2 駆動
- Capacity providers を使って ASG (Spot Fleet は使っていない) をコントロールしている
- ECS Task は普通のバッチジョブで、ワークロードが終わったら落ちる
- ジョブの定期実行に EventBridge Rules を使って1時間に1回起動する様にしている
念の為説明しておくと、 ECS のコンソールで、任意の ECS タスクを Scheduled Task として登録した場合、この EventBridge Rules による定期実行が作られる事になります。
なので ECS on EC2 でタスクの定期実行をしているユーザーは、基本的に今回のアーキテクチャの採用を執筆時点ではお勧めします。(今後改善されるかも知れませんが)
ジョブの失敗について
毎時0分、1日に24回バッチを定期実行しているのですが、1日に数回ジョブが起動していない事に気づきました。
EventBridge Rule のログを見ると Invoke は正常に行われていた様なので、 CloudTrail を使って RunTask の Event history を見てみます。

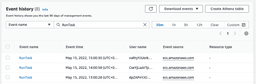
失敗した時刻の詳細を見てみると、
{
"eventVersion": "1.08",
"eventName": "RunTask",
// 省略
"responseElements": {
"tasks": [],
"failures": [
{
"arn": "arn:aws:ecs:ap-northeast-1:000000000000:container-instance/xxxxxxxxxxd9436481136bf6ccae8afa",
"reason": "AGENT"
}
]
},
// 省略
}
RunTask の結果が reason=AGENT で失敗している事が分かりました。
因みにこの EventBridge Rule ではリトライを3回までする様にしていますが、特にリトライは実行されていませんでした。この辺りの原因については後述します。


AWS サポートに問い合わせてみた
以上の事象について問い合わせたところ、回答としては以下の様な感じでした。
- CloudTrail が示している
responseElements.failures.reason=AGENTは ECS インスタンス内で稼働している ecs-agent サービスと ECS クラスタとの接続が切れており、タスクが配置できなかった時に記録される - ecs-agent は執筆当時の仕様上、1時間に数回程度クラスタとの接続を切断・再接続を行う場合があり、この時に一時的にクラスタとの接続が切れる為、タイミングが悪いとタスクが配置できない
- これは現状の ECS の仕様なので、完全に防ぐ術はない
- EventBridge Rules はこの問題でタスクが配置できなかった場合でもリトライは実行されない (※)
- Step Functions にリトライの仕組みを取り入れる事でこの問題を回避できる
※
EventBridge Rules がリトライできない問題について、事実としてそうなっているのですがこれについて仕様の詳細は分かっていません。
憶測になりますが、 Lambda や API Gateway などと違い ECS RunTask はタスクの終了を待ち、その結果を知る機構が (自分で用意しない限り) 無いからではないでしょうか。
以下、実験です。
ECS インスタンスに SSH で入り、次のスケジュールが実行されるタイミングを見計らい、 ecs-agent を止める為に ecs サービスを停止します。
# ECS インスタンス内
[ec2-user@ip-10-0-0-7 ~]$ sudo systemctl stop ecs
この状態で EventBridge Rule がタスクを起動しようとしてもタスクは配置されず、その時間の実行は (リトライも無く) それで終わってしまいます。

※上記画像は実験の為、タスクの起動間隔を5分毎にしています。
Step Functions を導入
作成する State Machine はシンプルな物で大丈夫です。単に ECS RunTask を実行する State を作るだけ。 (Resource は arn:aws:states:::ecs:runTask.sync)
リトライの部分だけお好みに調整して下さい。尚、ErrorEquals=ECS.AmazonECSException にしておくと単にジョブがエラーで落ちた時とかにはリトライしない様にできます。
以下は例です:
{
"StartAt": "RunHelloWorld",
"States": {
"RunHelloWorld": {
"End": true,
"Retry": [
{
"ErrorEquals": [
"ECS.AmazonECSException"
],
"IntervalSeconds": 30,
"MaxAttempts": 5
}
],
"Type": "Task",
"Resource": "arn:aws:states:::ecs:runTask.sync",
"Parameters": {
"Cluster": "arn:aws:ecs:ap-northeast-1:000000000000:cluster/sfn-test-for-scheduled-task-cluster",
"TaskDefinition": "hello-world",
"LaunchType": "EC2"
}
}
}
}

※Hello World は実際のバッチジョブを想定した適当なタスクです。
さて、こちらも実験をしてみましょう。先程行った通り、次のスケジュール時にタイミングを見計らって ECS インスタンスで ecs サービスを落とします。
# ECS インスタンス内
[ec2-user@ip-10-0-0-7 ~]$ sudo systemctl stop ecs
State Machine の起動と、1回目の RunHelloWorld State で RunTask が失敗している事を確認します。

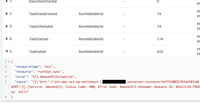
ここで適当なタイミングで ecs サービスを再度起動します。
[ec2-user@ip-10-0-0-7 ~]$ sudo systemctl start ecs
すると、State Machine の方でも2度程のリトライを経て最終的に成功している事が分かります。

CloudTrail で event history を見ても、2回の失敗の末3回目で成功している事が記録されていました。

気になる費用
Step Functions の執筆時点での料金は、料金ページによると月4000回の状態遷移まで無料、それ以降は1回あたり 0.000025USD と今回のユースケースではほぼ課金は心配しなくて良さそうです。
例えば毎分起動するジョブだと、全て成功した場合で (60*24*31-4000)*0.000025=1.016 と言う事で、この頻度でようやく 1USD 課金される程度です。勿論タスク配置に失敗してリトライが走る度に余分に 0.000025USD 課金されますが、頻度から考えても無いものと同様と考えて良さそうです。
終わりに
以上、 Step Functions を使った定期実行タスクのリトライ実装について紹介しました。
これって Fargate ではどうなんでしょうかね?個人の観測範囲で Fargate では reason=AGENT でタスク配置できなかった例を見た事が無いのですが、見た事がある方がいらっしゃればどこかで教えて下さい。
また、今回の実験に使ったインフラ構成についてですが CDK による IaC を用意しています。
https://github.com/issei-m/sfn-test-for-scheduled-task
になりますので、興味のある方は見てみて下さい。
タグ direct-ecs が Step Functions 導入前、
タグ use-sfn が Step Functions 導入後となります。
コメントを残す